In today’s world, everything seems magical when watching AI outputs, whether it is in the form of text, image, audio, or video. I know it can now generate multimedia formats or maybe anything in the future. But honestly, it will remain as magic if curiosity dies but becomes logical if you try to learn it, and in the end, you will understand everything is science, and these AI works on powerful, complex algorithms.
AI: Physical and Digital Domains
AI is itself a superset domain, which includes physical and digital AI. Meanwhile, Elon must be busy building robots that is physical AI; there is more to discuss about digital AI. LLM, which is known as Large Language Models, in simple terms, they are just language models but trained on a tremendous amount of data over the internet.
Large Language Models
We think AI came after GPT, but practically, it was actually introduced and heavily used before that, but where? It was used in text or speech translation tools. Yes, they were also using language models but with limited sufficient context size. The working of these language models is just to predict next words. In simple words, "AI has become super smart to predict next words based on the sentence context."
The Evolution of AI: Beyond GPT
Google released a research paper named "Attention All You Need." Don’t get confused with the title here; Attention has a special meaning, which you will know further. In this paper, they told that normally computers used (RNNs) method, in which it predicts or reads the word step by step, which works but is quite slow. So, they found a better alternative way and introduced the transformer, not an Optimus Prime, but in terms of computer, it has the ability to read and predict the multiple words at once and figures out how they can connect. This makes it faster and understand the long context of the sentences.
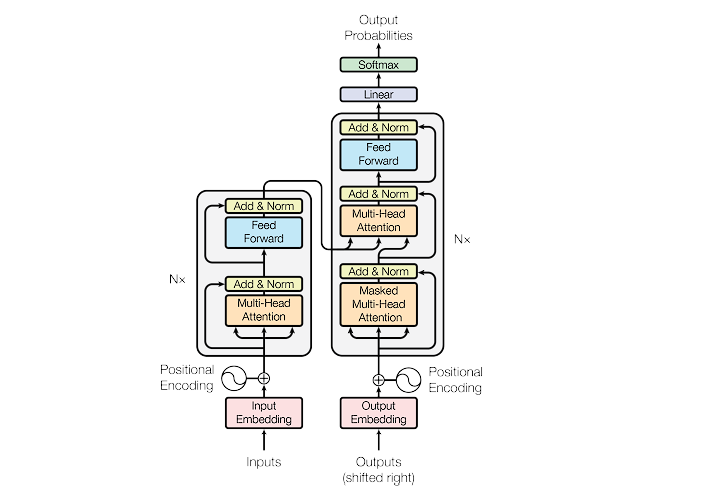
Transformers
Though this was done by Google in 2017 and implemented it to the translation feature, some of them have enhanced the potential of the transformer and gave birth to LLM, and as a result, we got ChatGPT, Claude, Gemini, Grok, and more. They have created their own transformer, but the base almost remains the same as in this paper. Let’s discuss some important concepts and components of the transformer. Usually, the transformer has two parts or is considered as a unit named Encoder and Decoder.
Inside the Transformer
Encoder
This is the initial part of the transformer; this is used to read the query as input and convert it to a machine-readable format, hence computers only understand numbers. There are certain processes to do it.
Tokenization: Breaking Down Language
In this, the sentences are broken down into tokens, known as tokenization; for example, "The Taj Mahal is situated in India," here individual words are tokens, but the word "situated" has two tokens, "situate" and "ed." Even a starting and ending identifier is also assigned with the token, like <START> <END>.
Indexing: Mapping Words to Numbers
Then, the next step is to map the index value based on vocab size. I mean, each token will always have the same but unique group of numbers.
Embedding: Creating Meaningful Vectors
Then, the next important step is creating embedding vectors; vectors are just coordinates, and it could be 3-dimensional or multidimensional, such as there could be thousands of dimensions mathematically, depending on the neural networks or trained data. Though the next word is predicted in this dimensional space, this is just a static embedding, and it has a drawback like "The cat sat on the mat" and "The mat sat on the cat"; both have different meanings, but there’s a high probability that the next word will be the same for these and may become meaningless for one sentence.
Positional Embedding: Preserving Order
To prevent this, positional embedding is used, in which one more vector is mathematically added based on the formula that determines the correct position of the words to preserve the semantic meaning.
Self-Attention: Weighing Word Importance
Here, each token also determines its self-attention property, such that where it should lie in the embeddings or sentence sequence. Here, attention is important because, while predicting the next word, that next word specifically depends on some words of the sentence, so attention priority is assigned to each word, such that changing some words may not change the sentence context or next predicted value; that means it is having low attention weight, or changing some words may change the whole context or next word, so that is having a high attention value.
Decoder
Though all this happens mathematically in multidimensional space and further it is converted to a human-readable format through the decoder.
Softmax (Temperature): Balancing Accuracy and Creativity
The accuracy of the output can be managed by the softmax parameter; it also determines the creativity level of the responses and manages that the response doesn’t deviate from the context.
Training LLMs: Data, Power, and Synthetic Growth
These LLMs are heavily trained on a huge amount of data, require lots of computational energy and hardware like GPUs, but almost all internet data such LLMs have now, since 2024, most are AI-generated data present over the internet, and this data is known as "Synthetic data." So, companies are highly focusing on increasing context window size, speed, and other aspects that responses could become better, natural, and less hallucinated.
There is more to this; you can refer to this document to get more detailed concepts: https://arxiv.org/html/1706.03762v7.